
OpenAI, the artificial intelligence research lab behind revolutionary chatbot ChatGPT, is developing a novel method to combat AI ‘hallucinations,’ a term used to describe instances when AI models fabricate information, according to a CNBC report. This development comes at a time when the issue of misinformation generated by AI systems is under intense scrutiny, especially in the lead-up to the 2024 U.S. presidential election.
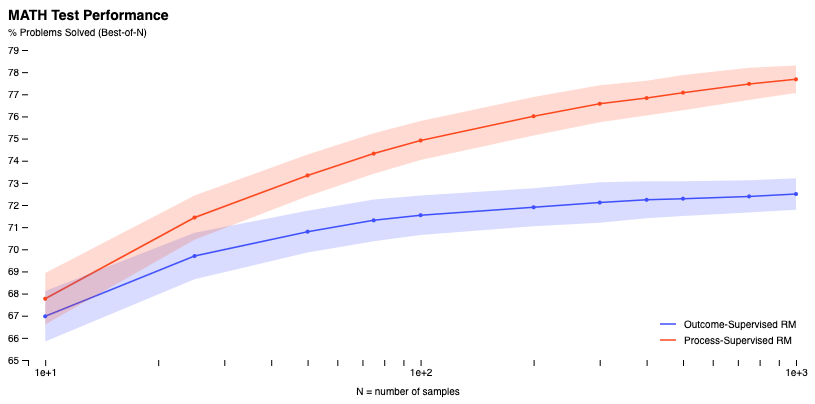
OpenAI, which has seen rapid growth with its ChatGPT model, powered by GPT-3 and GPT-4, is now exploring a new strategy to mitigate these fabrications. The “process supervision” approach involves training AI models to reward themselves for each correct step of reasoning when arriving at an answer rather than just rewarding a correct final conclusion. This method could lead to better explainable AI, as it encourages models to follow a more human-like chain of thought.
The research paper released by OpenAI, titled “Improving mathematical reasoning with process supervision,” provides an example of a challenging trigonometry problem. The problem requires the application of several identities in a non-obvious succession. While GPT-4 usually can’t solve this problem, the reward model correctly recognizes that the solution is valid. This example demonstrates the potential of process supervision in improving the reliability of AI systems.
The paper states:
“We’ve trained a model to achieve a new state-of-the-art in mathematical problem solving by rewarding each correct step of reasoning (‘process supervision’) instead of simply rewarding the correct final answer (‘outcome supervision’). In addition to boosting performance relative to outcome supervision, process supervision also has an important alignment benefit: it directly trains the model to produce a chain-of-thought that is endorsed by humans.“
Despite the promising results, some experts have expressed skepticism. Ben Winters, senior counsel at the Electronic Privacy Information Center, told CNBC that he would like to examine the full dataset and accompanying examples. He expressed concerns about the effectiveness of this approach in mitigating misinformation and incorrect results when the AI is used in real-world scenarios.
Suresh Venkatasubramanian, director of the center for technology responsibility at Brown University, also cautioned that the research should be seen as a preliminary observation. He noted that the research community needs to further scrutinize the findings before making any definitive conclusions.
OpenAI has released an accompanying dataset of 800,000 human labels used to train the model mentioned in the research paper. However, it remains unclear when the company plans to implement this new strategy into ChatGPT and its other products.
Featured Image Credit: Photo / illustration by “geralt” via Pixabay




